|
Enterprise Information Management using a Three-tier Client/Server ArchitectureH. J. Barnard, M. R. Hudson, A. D. Matz, M. L. Rathbun |
IntroductionCOMPAS is a document management system that provides quick and easy access to documents and document-related information throughout the product development life cycle. It was invented in 1984 to support product development documentation. Since then, COMPAS has gone through nine major releases, many minor releases, and supports customers outside of Lucent Technologies. It is the most popular full-featured document management system in Lucent R&D with over 6,000 customers and is recommended by the CIO as the R&D Document Management System. COMPAS started out as a centralized INGRES* forms-based application that saved document data in an INGRES* database and UNIX file system. It evolved into a more sophisticated application with an ASCII interface using Curses and written in C. Later versions became client/server oriented using TCP/IP networking. Then beginning in the early 90's workstations and PC's became common and COMPAS was rewritten using Tcl/Tk to support X-windows and then again using the Zinc* GUI Toolkit to support multiple PC and UNIX platforms. Many new features were added with each release. Also, each time COMPAS was rewritten to support a new platform, the application code behind the GUI also had to be ported and usually redesigned or rewritten. In January of 1997, the COMPAS Team began a radical change in architecture from a traditional two-tier client/server architecture to a three-tier architecture. We also decided to write the new client interface in Java in hopes of supporting a wider customer base, because it ran on multiple platforms, and to take advantage of the corporate intranet. This paper describes the benefits we found by converting to a three-tier client/server architecture, how we implemented the architecture, and how it helped us support an enterprise wide information management tool. We also share our experience using Java to write a GUI client application.
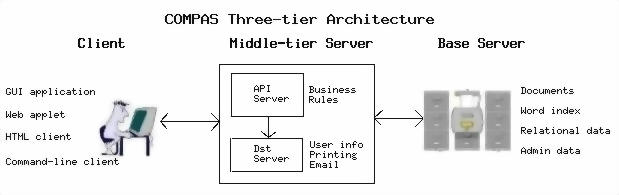
COMPAS Three-Tier Client/Server ArchitectureIn traditional two-tier client/server architectures, most of the business rules or work of the application is in the client. In a typical three-tier architecture, all communication from the client to the backend server is done through a middle-tier server that manages most of the business rules.
In our implementation of a three-tier architecture, we have
multi-platform clients, distributed middle-tier servers,
and several types of base servers. The messages and protocols
between each layer are the same. Therefore any client can
talk to any middle-tier server and any middle-tier server
can talk to an base server.
The client software exists as a web applet, a
workstation application, or a command-line application.
The clients access the middle-tier servers which may be duplicated
and distributed over several server machines.
The middle-tier server is really two servers - an application server
(API server) and a distribution server (DST server). The API server
delegates the responsibilities for certain site-dependent functions
like printing and getting user information to the DST server.
The reason for this delegation will be explained further below.
Each middle-tier server accesses several base servers for documents,
a word index, relational data and administrative data.
Figure 1 shows a picture of the COMPAS
three-tier client/server architecture.
Figure 1. COMPAS Three-Tier Client/Server Architecture We moved all the document management business rules from our previous release's client to the API server. In addition, we moved as much of the other work as we could from the client so that it would be as thin as possible. Anything that did not have to be in the client was moved to the API server. We only wanted the graphical interface components to be contained in the client. Of course, we had to provide some additional software to manage the control flow among graphical components, user data, and client-to-server communication. We wanted our base servers to be as fast and efficient as possible because they are not distributed and need to handle requests very quickly. So we moved as much work as we could from the base servers to the API server. The base servers are written in C++ and we spent extra time trying to make the data server classes and methods as fast and efficient as possible. Our API server became the brains of our new architecture. It contains all the document management rules, procedures, and methods. This gave us an opportunity to completely reorganize our document management software into object feature packages where each package contained many methods or functions. We created and documented an interface to these packages that we refer to as the COMPAS API. The interface to the COMPAS API from any client is a TCP socket connection. A client opens a TCP connection to an API server on a given machine and passes a defined message with various arguments to indicate which document management feature to invoke. The protocol between client and API server is simple, but non-standard. The most important factors in creating the document management features were to organize them logically, and to organize them so that client access to the API server is minimized. For example, our old client had to access the base servers two or three times in some cases to perform a single "feature". We organized feature packages so that the feature would only require one API server access. We wrote all of the middle-tier server in C++. We had a number of objectives such as moving as much data thru the API server as quickly as possible, trying not to leave client or base server connections up between transactions, and handling all the error diagnostics that get sent back to the client. We spent much time re-designing many of the API features to improve performance. Since our API server does the bulk of the work, we made sure that our architecture supported distributing this software across multiple server machines in an attempt to distribute the load. The work delegated to the DST server from the API server turned out to be very important. We realized that we needed to support features that related to local user machine environments such as printing, email, and user authentication. This separation from the API server is necessary because there are cases where groups of users sharing the same API server require different DST servers. These DST servers are dependent on the printing, email, and user identification software of a specific machine and must reside on those machines while the API servers could reside on any of the server machines. The COMPAS project realized several benefits from having the distributed API server do all the work:
MaintainabilityIn a two-tier architecture, the client does most of the work and consequently, when the software must be changed, it has to be changed on every user's workstation. In a PC environment, this means potentially thousands of new installs. We eliminate those new installs using our three-tier architecture. The API server does most of the work and so most of the software changes will occur in that server software. The clients are no longer impacted by most of the required software changes. Our API servers are hosted on UNIX machines and are controlled by COMPAS administrators and developers. Changes to the software are made simply by copying the new executable servers to their respective UNIX hosts. These changes are transparent, available immediately to every client, and can be made as often as needed. A good example of a rule change in COMPAS is support of a new document type. The rules for recognizing and dealing with different document types (e.g. MS Word, Framemaker) are part of the API server. After adding to the API server the rules to handle a new document type, no change is needed in the client to handle it.
ScalabilityOur base data servers are centralized to one or a small number of server class computers. Because they also give up code to the API server, they are able to support more transactions per unit time. The API servers are distributed across as many machines as possible, either workstation or server class computers. Supporting new groups of users is as easy as distributing the API server to their computers. The BCS installation of COMPAS comfortably supports several thousand users. We did this by making the API server runnable on every workstation and server in Denver, Holmdel, Columbus, California, and several international locations.
ReusabilityIn the last 5 years, COMPAS has been ported 3 times to different platforms and user interfaces. We know well how long it takes to port so much application code along with new GUI code. The ability to support new clients, with different user-interfaces, without changing the application code is very important. It took about 16 months to encapsulate all the document management functions into an API server resulting in around 50,000 lines of code and a few months to port the backend servers resulting in about 10,000 lines of code. It took about 18 months to create a GUI client that uses the API server which is about 40,000 lines of code. The real benefit is from here on out. We hope to never have to port application code again. Given the pace at which things have changed in the last five years, we know that in a short time another platform will arise and there will be a need for it to interface with our application. In fact it has already happened. After developing our full-featured client using Java, we saw a need that was not being met. Many users only had need for read-only type of access and were coming in via the intranet. Using simple HTML forms and cgi-bin scripts that communicated with the API server we were able to provide this simple access in only a few days. COMPAS always had UNIX command line access to the application, but it was only a small subset of the features. In this release, we decided to provide access to all the features from a UNIX command line application. The command line application was easily created because it accessed the API server to do most of the work. At this point, we have provided five different clients that access the API server to do their work. They are a cgi-bin script that users embed in their own web pages to obtain a single document in multiple formats from COMPAS, a simple HTML forms based interface, a full-featured web browser applet, a full-featured client application and a full-featured command-line client. The code that make up these interfaces can be used as examples for others who want to write applications that use the COMPAS API. Tools that give users real choices on how things are done are better than those that don't. Having an API server gives users the ultimate choice of completely providing their own client interface. Users may want to encapsulate a certain workflow associated with special needs of their process, or support a new platform. All that is possible while still having access to the same underlying document management data as those using the standard clients. By presenting a consistent, accessible interface to the API server, any client, not just the COMPAS Team-provided clients, can use it. We know of two projects that are providing their own client interfaces to their document data via our API server. One is the Network Systems Signaling project [1], and the other is the Internet Telephony project [2].
TestabilityWe knew before we started to implement this architecture that the maintainability and reusability would be great benefits. It was a pleasant surprise that testing was also made easier. Since the middle-tier and base servers can be tested with any client, we didn't have to use the GUI client for testing. Testing a GUI is either a laborious manual process, or requires a sophisticated record and playback testing tool. Even though we didn't use any of the Java based testing tools, we have had experience with one other GUI testing tool and knew we wouldn't have the resources to use one. The GUI was tested manually and this would also test the functions of the servers. Instead of the Java client, we used our UNIX command-line client to test the servers. We were able to write simple UNIX shell scripts, using the command-line client, that exercised most of the features of the API server. Shell scripts are much easier to maintain than other recorded test scenarios we have had experience with. It is much easier to run scripts to test the API server rather than manually run the GUI client. The UNIX scripts could also double as regression tests when bugs were fixed or new features implemented. With the addition of some 'Enterprise' [3] features built in to the UNIX command-line client, the same testing scripts are also used to sanity test new customer installations.
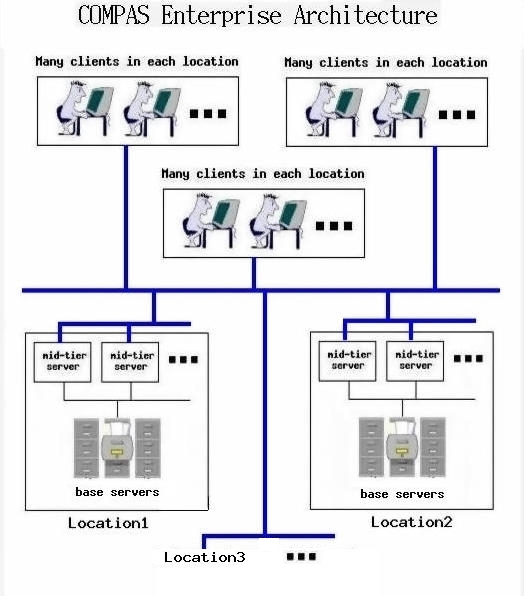
Enterprise-wide Information ManagementWe believe that the biggest win with our new three-tier architecture is that we now more naturally and easily support an enterprise-wide information management tool. Users at one COMPAS location can now access document management information at another COMPAS location all from their same client software. They can search, browse, and print information located over the entire enterprise from a single client. In fact, by resetting server preferences, a user can access all the document management features at a remote COMPAS location from their COMPAS client.
Figure 2. COMPAS Enterprise Architecture The new architecture, shown in figure 2, allows each project to maintain a separate installation or instance of COMPAS. It can exist on their own servers using their own relational database and storage mechanisms. They are responsible for the maintenance of their own servers and data. Their COMPAS instance is only accessible from outside their community via their API servers. Local projects can create and manage smaller groupings of documents and related data in addition to having the ability to easily access other location's information or to search enterprise-wide for information. Since every COMPAS API server at each location has an identical interface, a user can access the information at another location simply by pointing their client at that location's API server. The protocol and messages between each server tier are the same. Therefore, any client can communicate with any API server. The advanced search feature in the COMPAS client provides the user with a list of remote COMPAS installations that can be searched. This list is administered per location. The base servers at each COMPAS location can support different organizational strategies and databases. API servers can be distributed across many machines at one location, but as figure 2 shows, they are administered to talk to only one set of base servers. We could not completely provide enterprise access of information at a remote COMPAS in our new architecture without the notion of the DST server shown in Figure 1. The DST server's only job is to manage site specific information for each user. Therefore, a user accessing information at a remote COMPAS location takes with them a reference to their own DST server. This is implemented by having the client tell the API server that it is accessing, which DST server to use. If a user performs operations at a remote location that require printing, email, or user information, then the API server at that remote location will delegate that job to the user's personal DST server that it was given. A user cannot actually perform operations at a remote installation of COMPAS that result in modification or change to the data at that installation unless they have registered with that location and have a COMPAS login. This is guaranteed by the fact that an API server will not perform update operations without authenticating the user against the "local" user information base. The user information contained in their personal DST server must be matched identically with local base server information for users at that site.
Using Java to Develop a GUI ClientAs discussed earlier, the COMPAS GUI has gone through a metamorphosis from an INGRES forms based application to to a thin client application written in Java. In January of 1997, the COMPAS Team began a complete rewrite of the COMPAS GUI in Java. In this section, we will discuss the history of that development, the lessons learned, the struggles, and the successes. In early 1996, Jack Barnard, the COMPAS Team Leader, implemented some of our key features as web based applets. This effort proved the viability of Java for use in the COMPAS GUI and laid the groundwork for the migration to Java. In early 1997, two COMPAS developers began to rewrite the COMPAS GUI as a thin client in the Java programming language. The first big decision we had to make was which Java Development Kit (JDK) to use. The JDK 1.0.2 was stable and in use while the JDK 1.1 was just in beta. We wanted to run the client as an application and as an applet in a web browser but the browsers only supported JDK 1.0.2. Also, the new JDK release represented such a large change that it had many bugs. We considered many factors that lead to the decision to use JDK 1.0.2. The second big decision that we had to make was whether to write the Java code by hand or to use an Integrated Development Environment (IDE) or GUI builder. We investigated the two most popular GUI builders at that time: Marimba's Bongo* and Symantec's Visual Cafe*. We decided that Bongo did not give us the flexibility or control over the GUI that we felt we needed. We also believed that the Visual Cafe widgets had a cleaner, more professional appearance. So, Visual Cafe was selected as the GUI builder we would use. We began our development using JDK 1.0.2 and Visual Cafe 1.0. Using Visual Cafe, we were able to produce a large number of very good looking GUI components in a reasonably short period of time. However, we discovered that the code that was produced by Visual Cafe was not easy to maintain, and was not up to the quality standards that had been set by earlier COMPAS projects. Worse, there were many bugs in the generated code that had to be corrected by hand, and some of the code would run on the Windows OS but would not run on other platforms such as UNIX. We had to rewrite that code so that it worked on all platforms. Visual Cafe also generated code using absolute coordinates in pixels for the window components instead of a using a layout manager [4]. The result was that GUI components looked great on the Windows OS but looked terrible on other platforms that used different font types and graphical drawing tools. We decided to write our code by hand using the templates that we had already established. The new JDK 1.1 release was becoming more attractive to us because it had a lot of features we wanted to use. Also, the longer we waited to convert to 1.1, the larger the porting job. So, we switched to JDK 1.1 and dropped the use of GUI builders reversing our two most important decisions at the start of the project. When we started using the JDK 1.1, it was in its first year and had a large number of bugs and a lean set of features and graphical interface components. We spent much of our time trying to find workarounds for the bugs. We also spent a lot of time developing even the most primitive components such as tables, progress bars, bordered panels, status bars, tool bars, dialog boxes, wrapping text labels, image buttons, and much more. Each time a new release of the JDK came out, we scrambled to download and install it in hopes that our huge list of bugs and outages would be fixed. In some cases, bugs were fixed, in most cases what worked in the previous release stopped working and we had to find workarounds again. Currently, The Java programming language shows a great deal of promise as a multi-platform, object-oriented programming language with embedded graphical interface toolkit. In our experience, it has come a long way in just a couple of years. Most of the features now work, they are efficient, and there are many new graphical components. If you exercise care, the software you develop with Java can be truly multi-platform. Additionally, the performance of the Java Virtual Machine has improved greatly. In the beginning, the entire process of developing with Java was very frustrating but within a year and a half, the JDK and our own software started to come together nicely. The human factors associate we worked with was impressed with our ability to implement most of the components that he designed with relative ease. One of the developers working on the Java client software was an experienced C programmer but did not have experience developing object-oriented, multi-threaded, event driven applications. After an apprenticeship of about 8 months, he had enough confidence to develop classes on his own that were very nicely done in our opinion. We attribute this quick startup time to the easy-to-use nature of the Java programming language. In the past year and a half developing our latest release, a lot of our client software was rewritten to take advantage of new features in the JDK. Also, much of our software was thrown away because Sun came out with new graphical components that we had already implemented. Their components were not necessarily better than our own but we used them because it reduced our supported code base. Our client code base is now over 45,000 lines of code, produced by 2 developers in a year and a half even though we rewrote and discarded a lot of software over that period. Further, one of the developers did not have object-oriented development experience at the start.
SummaryDocument management has become very important to our business. COMPAS has been providing a powerful, flexible document management solution for Lucent for 15 years. Choosing a new architecture, more appropriate to the task, we have provided a solution that is easier for us to maintain and gives our customers better features. It scales enterprise-wide and still gives all the advantages of project level control. By using Java as our main client delivery platform we support many more platforms and stay right at the front of the increasingly important use of our corporate intranet.
*Trademarks
INGRES is a registered trademark of The Ingres Corporation
Footnotes[1] QDI Document Interface.[2] ITS Document Interface. [3] The UNIX command line provides arguments to specify a different machine to contact for access to an API server rather than the default 'localhost' machine. [4] A year after this experience one member of our team attended a class on Symantec Visual Cafe Version 2.5. Since our first experience we have learned that the product has matured and now supports Swing widgets and Layout managers and will very shortly support the new 1.2 JDK.
|